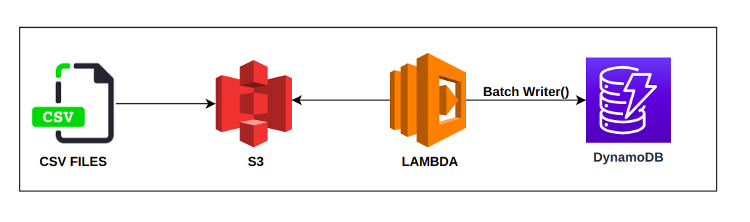
We faced a use case with a web application requiring millisecond scale results from the database. We had around 500,000 records under a s3 bucket to be ingested into the DynamoDB table.
PutItem API
A provisioned DynamoDB table with default settings (5 RCU and 5 WCU) was created with the Partition key (ItemID) and when called with the put _item API call via Lambda, the process was ingesting one record at a time which was sufficient for a record ingestion of a smaller dataset. In our case, the dataset was large and the provisioned table was very slow for ingestion often leading to throughput error or Lambda timing out.
Batch_writer()
With the DynamoDB.Table.batch_writer() operation we can speed up the process and reduce the number of write requests made to the DynamoDB.
This method returns a handle to a batch writer object that will automatically handle buffering and sending items in batches. In addition, the batch writer will also automatically handle any unprocessed items and resend them as needed. All you need to do is call put_item with table batch writer to ingest the data to DynamoDB table.
Configurations used for DynamoDB.Table.batch_writer():
- We structured the input data so that the partition key(ItemID) is in the first column of the CSV file.
- We created a DynamoDB demand table with On-Demand for the Read/write capacity to scale automatically
- Lambda Function with a time out of 15 minutes, which contains the code to export the CSV data to DynamoDB table
- Ensure the IAM roles associated to the services are configured
Once configured, we tested the Lambda function, the records successfully loaded into DynamoDB table and the whole execution just took around five minutes.
Serverless and Event Driven
The whole pipeline was serverless and the lambda function was configured with the S3 event trigger with the prefix (.csv). An overall architecture and data flow is depicted as below