No matter what kind of data science projects one is assigned to, making the sense of the dataset and cleaning it always critical for a good approach.
Problem Statement
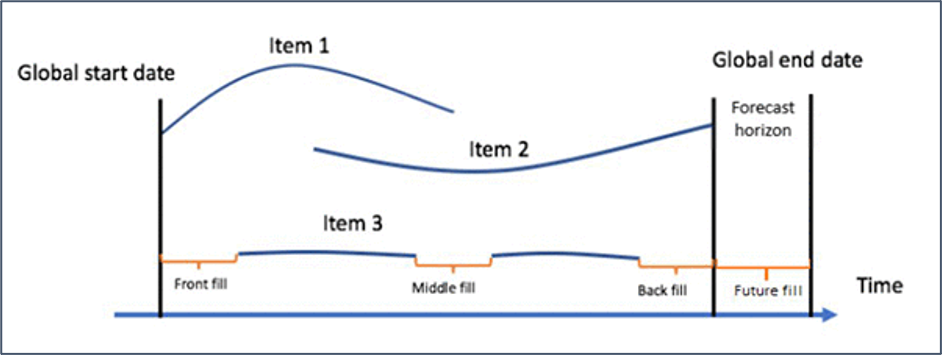
We have a hierarchical data for products for a Retail Store for different categories from three states namely, California, Texas and Arizona. Looking at this data, we need to predict the sales of products for one month (30 days). The training data consist of individual sales for 305 days. Using this training data, we need to predict the upcoming days.
Analyzing Dataset
Before ingesting the target time-series data to Amazon Forecast, the first step is to start with Data Analysis.
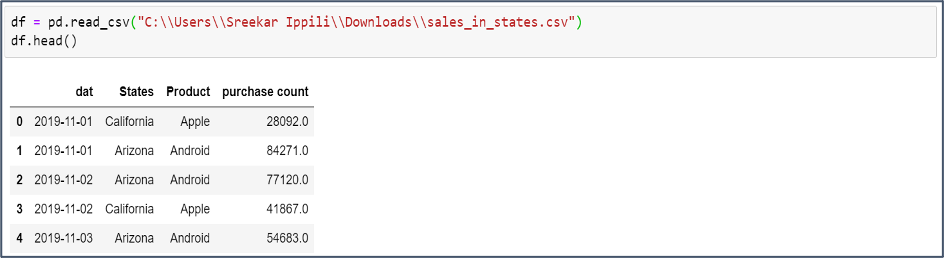
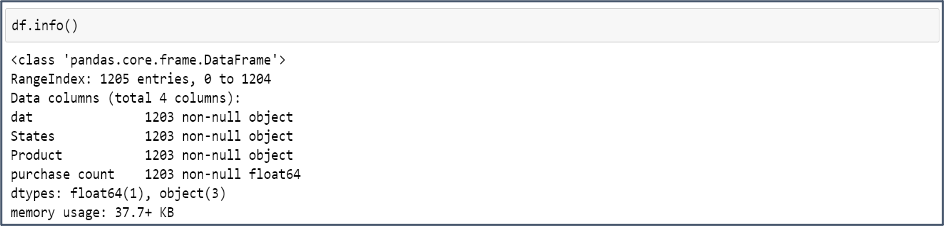
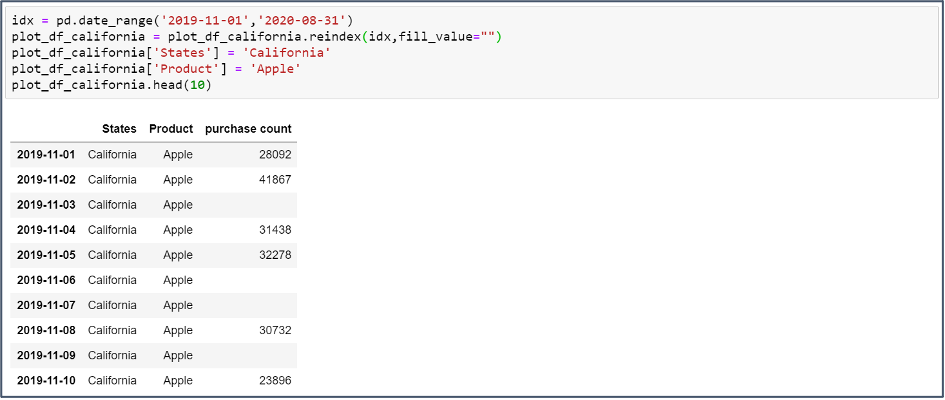
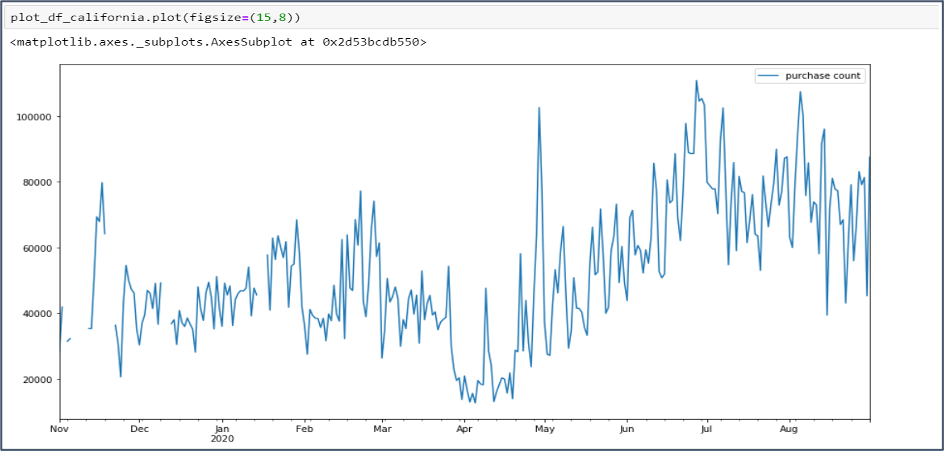
It helps us to understand the data by identifying trends and data gaps. To start with, Exploring the Dataset, we use the Python Pandas Library to read the data and print the first few rows.