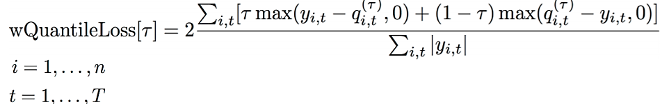Use case background
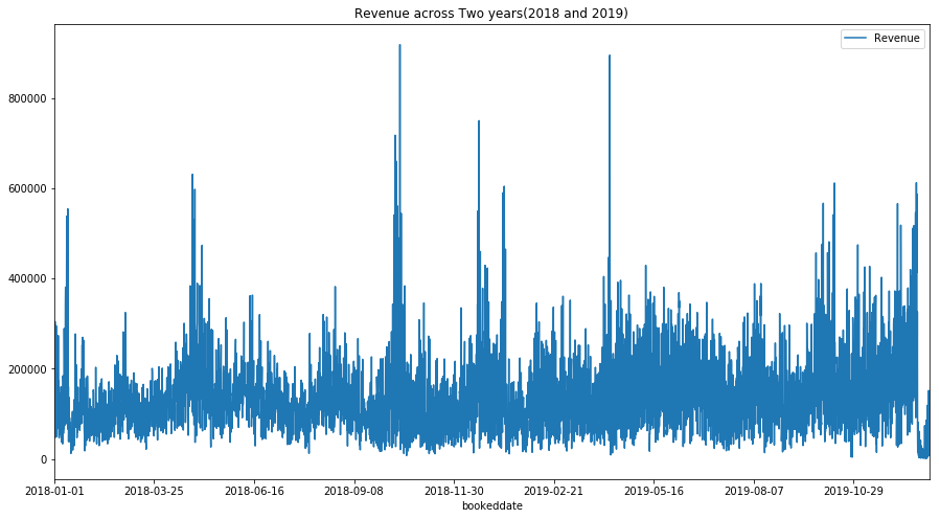
Online Transport’s eTicketing business aggregates thousands of bus operators, each offering transport services across diverse routes vehicles, pickup times, and service levels . Revenues vary widely by operator. and there is also variability, independent of the operator. For example, revenues are subject to seasonal fluctuations in travel related to weekends, customer demographics, holidays, and other related data.
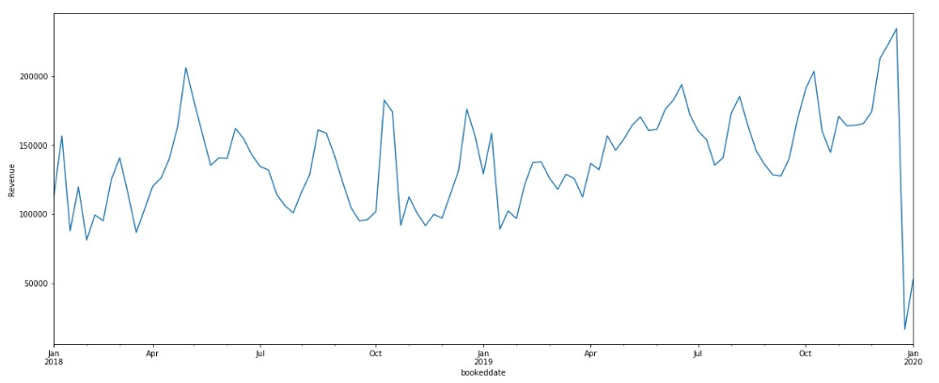
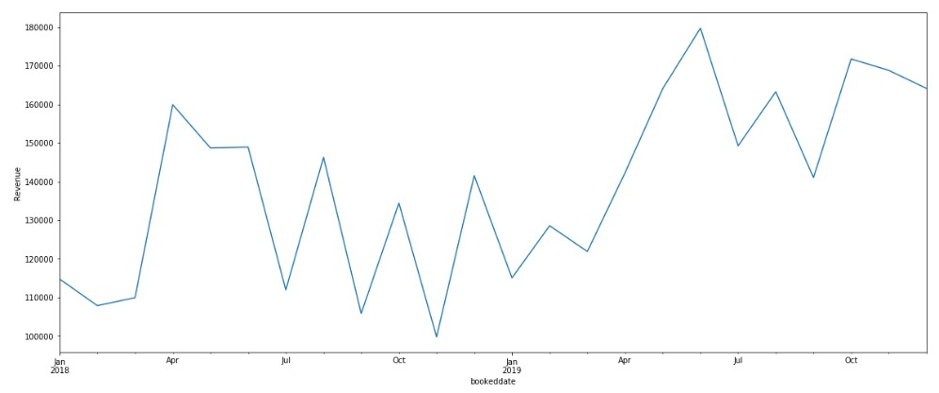
Given the variability in factors that affect revenues, it is critical for the eTicketing business to develop Sales and Operations processes (S&OP) that allow them to accurately forecast the future daily from multiple transport operators. Over and under forecasting are both costly mistakes for these mistakes for this business and greater accuracy leads directly to cost efficiency and strategic insights into the revenue performance.
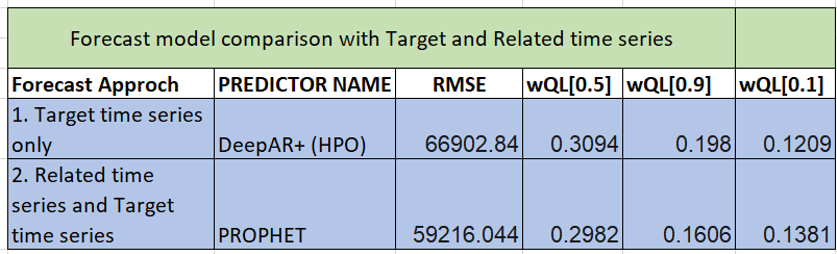
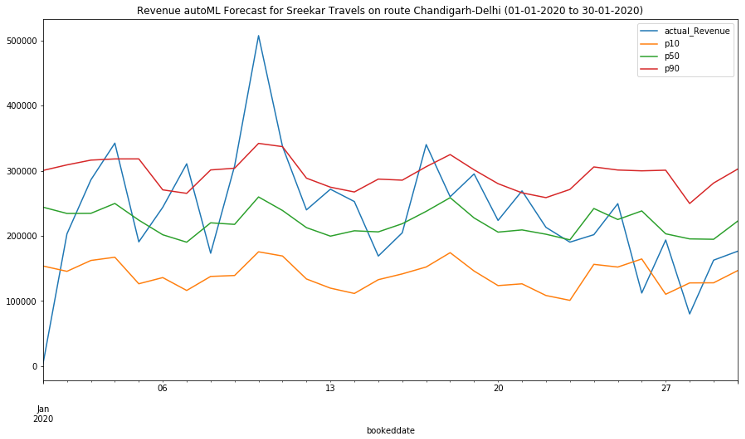
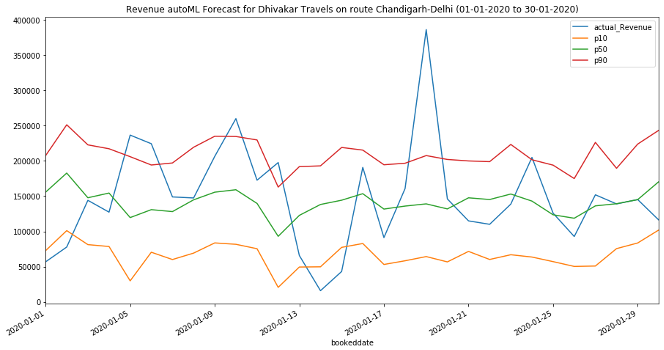
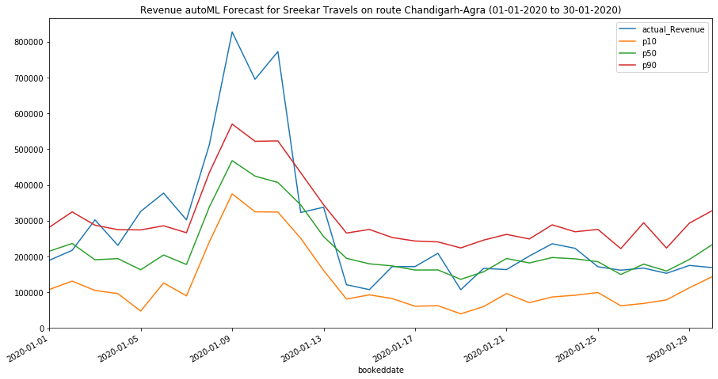
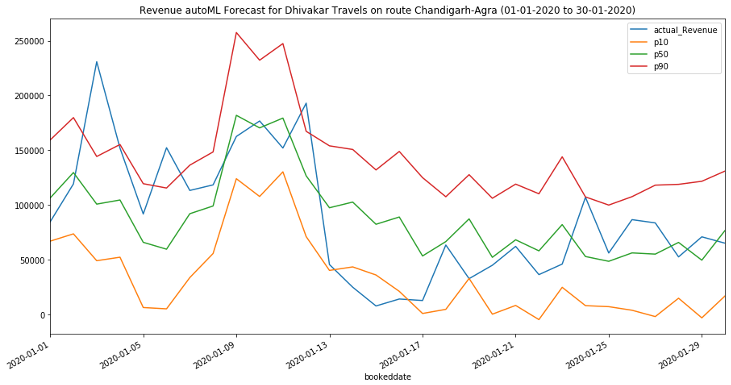
Most other forecasting solutions generate average, point forecasts. However, there is a greater need to factor in uncertainties in the forecasting. This means the forecasts ought to cover not only one possible future but all possible futures which is statistically any quantile value between 1% and 99% denoted as P1 to P99, including mean or the point forecast denoted by P50,with the appropriate weighting according to the probability of a particular outcome. To this end, the key enabler for downstream decision making is a full distribution of the forecast values rather than just having a point forecast., Amazon Forecast generates probabilistic forecasts at a quantile of your choice. In this case, we have considered three default quantiles: 10% (P10), 50% (P50), and 90% (P90). P10 and P90 being under and over forecasts helps quantify the chances of future revenues. Amazon Forecast also allows businesses to define custom quantiles to meet their business needs.
For the P10 forecast, the true value is expected to be lower than the predicted value 10% of the time.
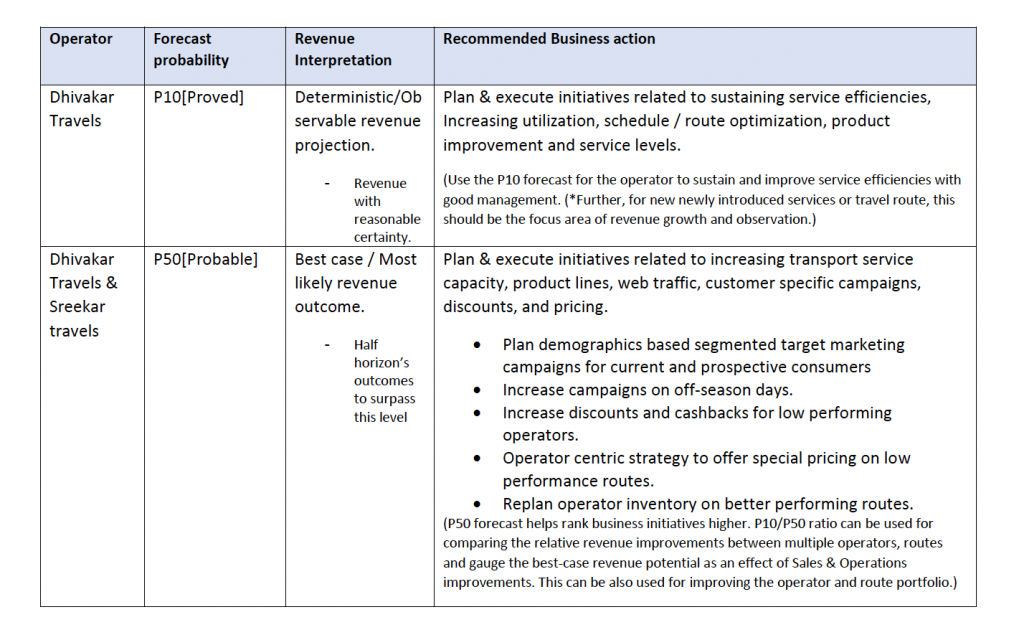
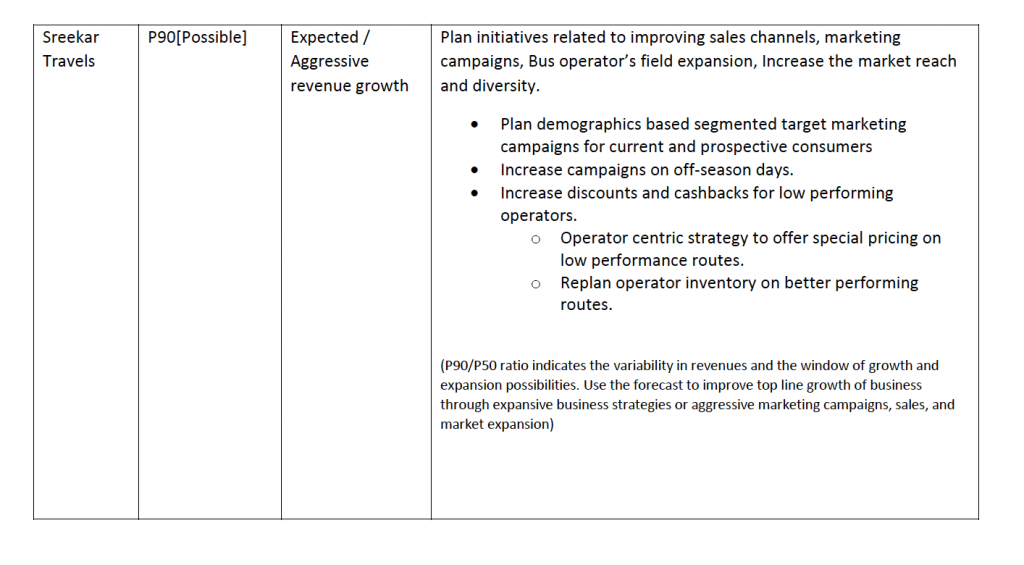
With greater accuracy, deeper insights, and visibility into multiple scenarios through Amazon Forecast, the eTicketing operator could take the following steps to optimize their marketing and operations to increase the eTicketing revenues.
- Increase the market campaigns for specific target demographics. For example offering discounts for target customers unlikely to use the service, and loyalty programs for high value customers where churn is costly.
- Improve e-Ticketing sales by offering incentives to key operator segments, to reduce the drop out ratio in the e-Ticket bookings
- Improve the visibility of the bus operators with lower forecast revenues in the search page of consumers in the e-ticketing App to improve ticket bookings.
- Increase the ticket discounts and wallet cashback on the lean days identified in the forecast horizon.
- Plan a strategy with Bus operators with lower revenues to offer special pricing on identified routes as well as to replan services on profitable routes to improve customer adoption and revenue run rate.