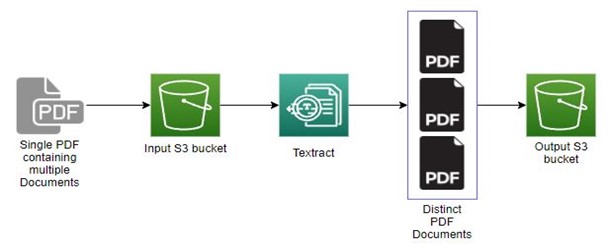
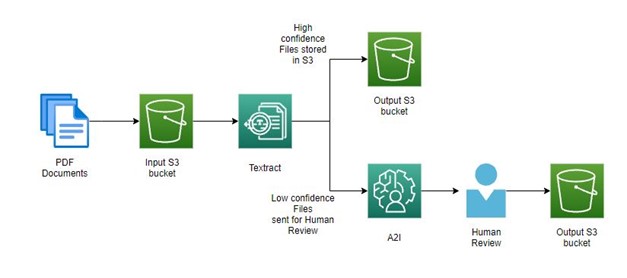
In this blog, we will explain how 1CH improvised the functionality of Amazon Textract by developing a custom workflow solution by integrating with AWS Step Functions, AWS Lambda and AWS SNS making the above super-sized documents process easier and quicker.
Extracting required data from a document manually may be quite simple. But extracting data from hundreds of documents manually daily is not as simple as that. It takes a significant amount of effort and time to complete the action, and it is prone to error.
There are several intelligent document processing tools available to automate and speed up the process of extracting and processing data from documents, thereby reducing the risk of errors.
Leveraging Amazon Textract, data in documents can be processed more efficiently and quickly. Amazon Textract uses machine learning to automatically extract text, tables, and form data from scanned documents, making it a powerful tool for intelligent data extraction.
BUSINESS CHALLENGE
Every business in our world deals with hundreds of documents daily. Especially in custom business, there are various documents like invoices, lading, containers, and packing lists, etc. in which people manually extract the data from the respective documents, which is a tedious process. Another challenge faced when dealing with supersized documents is segregating the single document into distinct documents according to its file type.
1CH improvised the functionality of Amazon Textract by developing a custom workflow solution by integrating with AWS Step Functions, AWS Lambda and AWS SNS making the above super-sized documents process easier and quicker.
AMAZON TEXTRACT
Amazon Textract is a machine learning (ML) service that uses Optical Character Recognition (OCR) to automatically extract text, handwriting, and data from scanned documents such as PDFs. Textract is used to detect and extract key-value pairs in documents and structured data stored in tables without any manual intervention and with higher accuracy.
AMAZON AUGMENTED AI
Amazon Augmented AI is a machine learning service that makes it easy to build the workflows required for human review. A2I can be used to review certain files for human oversight to ensure accuracy.
STEP FUNCTIONS
AWS Step Functions is a low-code visual workflow service used to orchestrate AWS services and automate business processes, managing failures and retries without any human intervention.
SOLUTION APPROACH
The business challenge when dealing with many documents to extract data from hundreds of PDF documents and split combined PDF documents into distinct PDFs based on document categorization can be simplified by using the above Amazon services.
SPLIT PDF DOCUMENTS
We established a pipeline leveraging S3, Amazon Textract, and Lambda to split PDF documents accordingly.