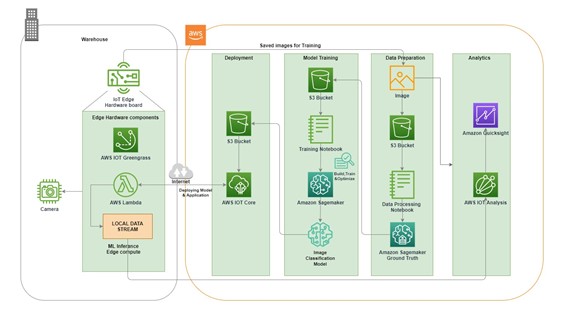
This blog illustrates leveraging Amazon SageMaker and Amazon IOT Greengrass to develop an Image Classification ML model and deploy it on the Edge to detect objects.
The Image classification ML technique is used in manufacturing and assembly units to keep track of all the parts that are used and enables packaging inspection, barcode reading, and quality inspection automatically.
AMAZON SAGEMAKER
Amazon SageMaker is a fully managed machine learning service. Users can quickly and easily build and train machine learning models, and then directly deploy them into a production-ready hosted environment managed by AWS.
AWS IOT GREENGRASS
AWS IoT Greengrass is software that extends cloud capabilities to local devices. This enables devices to collect and analyze data closer to the source of information, react autonomously to local events, and communicate securely with AWS IoT Core and export IoT data to the AWS Cloud.
SOLUTION APPROACH
Image Classification ML model can be built in AWS using the above services and deploy to the edge for inference.