1. Industry
“AI specifically Machine Learning” has come a long way from being just another buzzword in the IT Infrastructure software products space to become a key differentiator for enterprises worldwide when choosing solutions to manage their IT platforms.
Intelligent inference for anomaly detection and auto-healing can clear the noise and help focus on tasks that drive real value. Therefore, new age ISVs in this space are investing in adding AI features of predicting, anomaly detection & auto-healing capabilities.
2. Problem of Datasets for Modelling (AI/ML)
Machine Learning models, as any data scientist will tell you are only as good as the data that is used to build them. For any product to be created using machine learning, large volumes and variety of data needs to be fed to the model to train it, before it can be launched for production use. Also, datasets need to be generated under varied scenarios to evolve and mature the ML models. And here in lies the real problem. Enterprises are not going to share their production data from live systems for ISVs to develop their products. So, where would ISVs get all this data regularly?
3.Solving the Dataset Problem
The answer is for ISVs to create their own data, to train the models by running simulations. Creating data in itself is a fairly involved process and it pays dividends to have a standard approach to creation of such data sets. Especially, when the ISVs are targeting multiple tech stacks and variations as targets for their products.
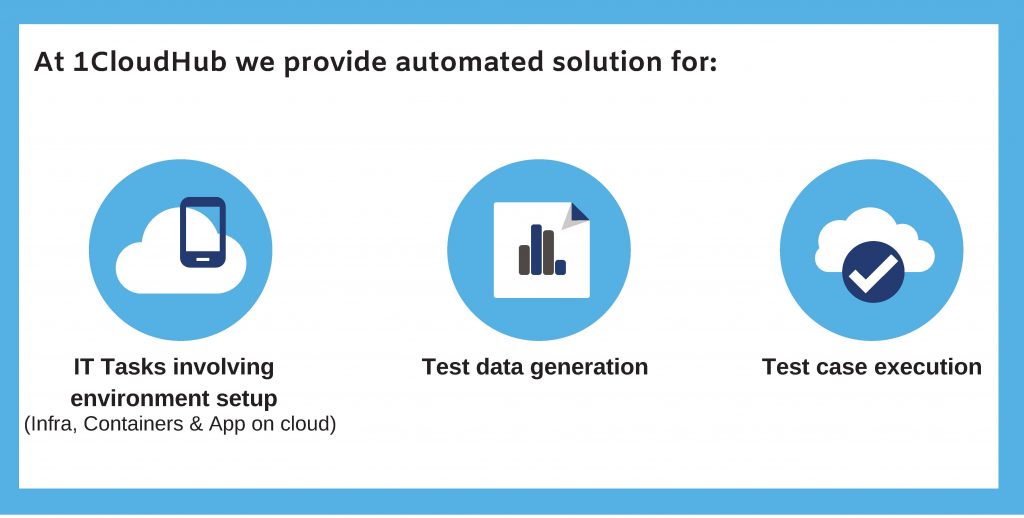
1CloudHub Nimbus Automation framework is spread across 3 phases:
- Environment creation for deploying target tech stack, monitoring tools and data generation systems.
- Generating test data and simulation scenarios for the target tech stack to be monitored.
- Running the simulations and monitoring to generate the metrics data to be used in ML model creation.