Customers today find themselves designing large and complex business flows such as image processing, media transcoding, data pipelines, etc. A trending addition to such a scenario would be MLOps.
Traditional approaches for such scenarios is either a monolithic design, where a single component would be performing all the functionalities or a complex queue(s) + service based architecture with polling.
One of the downsides of going with a monolithic design is the complexity involved in adding/modifying functionalities/processes. Also, scaling the application is challenging and there is limited reuse realization.
In a cloud-based world, the application built must also be capable of integrating with multiple services. A solution to offset such challenges would be to design a distributed workflow.
Distributed Workflow
In a distributed workflow, such large and complex business functionalities are broken down to rudimentary components thus addressing some of the key downsides of monolithic design.
Since there are multiple components working together to achieve a common functionality, there is no single point of failure and each component can be scaled independently without impacting one another. But how will those components interact with each other?
Orchestrator
An orchestrator is one of the components of a distributed workflow architecture that maintains the relationship and handle dependencies between the components. Adding to the surge in the complexity of the design and debugging of a distributed architecture, this orchestrator component needs to be built which is expected to have the following features.
- Easy to build/develop and modify
- An operational management layer to have a bird’s eye view of the orchestration and the current execution
- Ability to catch and handle errors as well as a seamless retry logic
- Tracking and Logging
- Quick integration with multiple different components and interfaces with module reusability
Developing such an orchestrator from scratch is a daunting task considering the complexity of such a component, provision of separate processing and storage capabilities, addressing network latency between components etc.
While, serverless orchestration can solve some of the drawbacks of a custom orchestrator made from scratch as there is increased agility and lower total cost of ownership, the other complexities do persist.
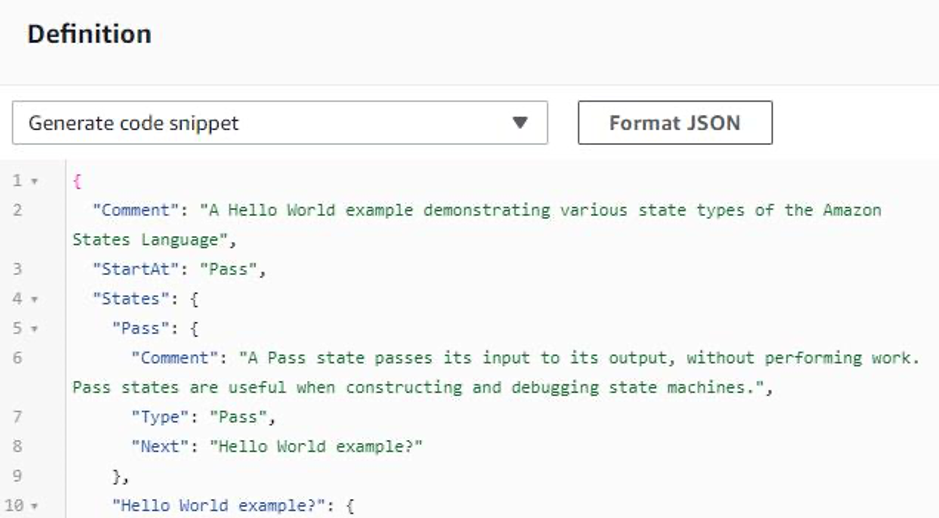
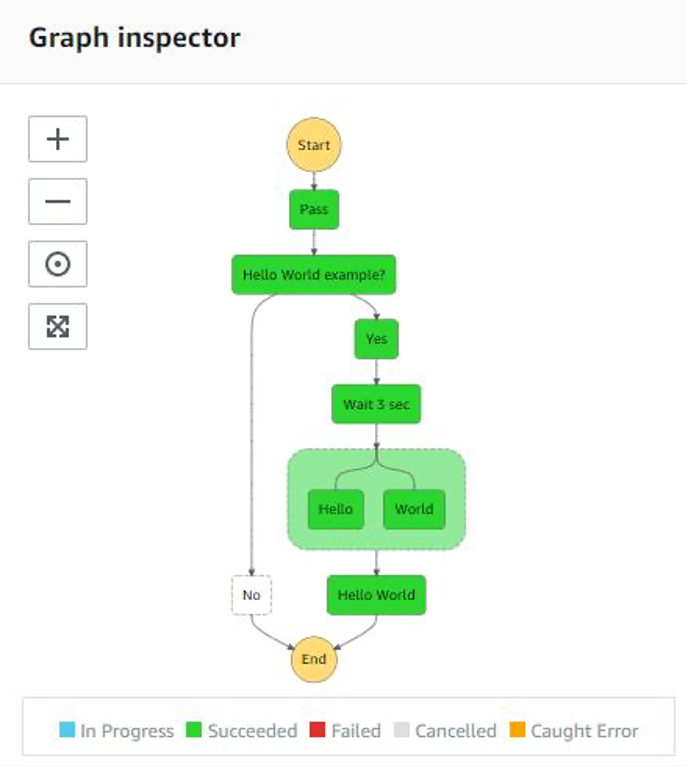
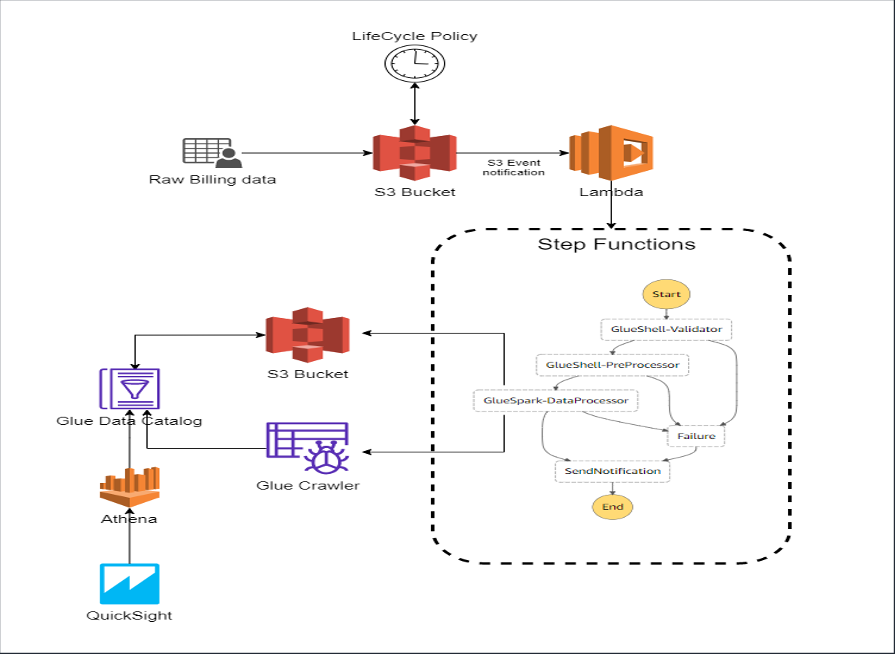
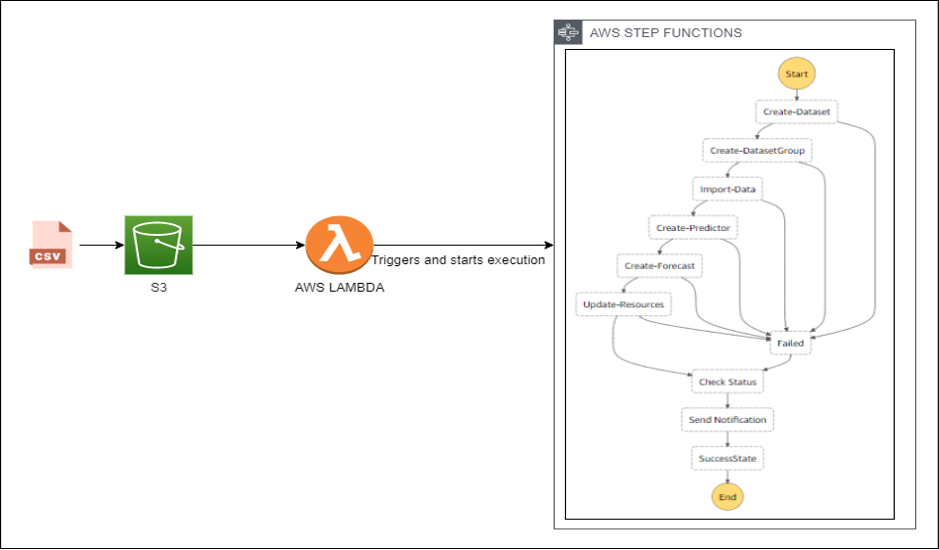
In this article, we will have a look at AWS Step Functions and how it’s integration with other AWS services can help in overcoming the drawbacks of developing a custom-built orchestrator.