As data volumes grow exponentially, traditional data warehousing solutions often struggle to meet the increasing demands for scalability, performance, and advanced analytics.
Shifting to Amazon Redshift provides organizations with the potential for superior price-performance, enhanced data processing, faster query speeds, and seamless integration with technologies like machine learning (ML) and artificial intelligence (AI).
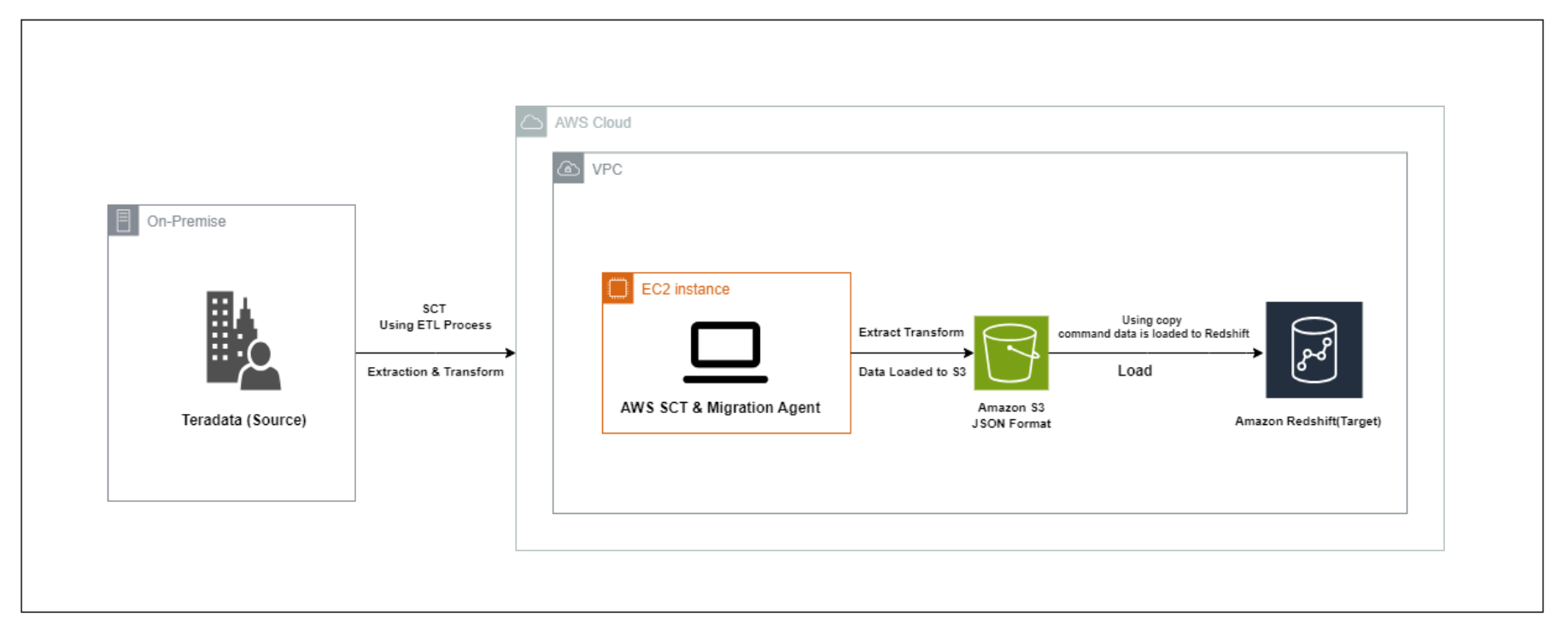
As organizations face increasing pressure to modernize their data infrastructure and harness the power of advanced analytics, migrating from traditional on-premises systems to cloud-based solutions has become a critical step. One key decision is transitioning from legacy platforms like Teradata to modern cloud data warehouses such as Amazon Redshift. The migration from Teradata to Redshift enables organizations to overcome the limitations of traditional systems by improving scalability, performance, and cost-efficiency.
Using AWS tools like the Schema Conversion Tool (SCT), we aim to seamlessly convert the schema, code, and data to ensure compatibility with Redshift while maintaining data accuracy and minimizing disruption to business operations.