Challenges and strategies to ingest data to Data Lake on AWS
This blog focus on the use of AWS services to overcome the challenges faced in ingestion of the data with a faster and secure approach to the Data lake.
The current era requires quick and real-time access to the data. With increasing numbers of people accessing data, it’s important to have flexible and scalable data platforms. Hence people switch to cloud to achieve these objectives without compromising on security. However, the key challenge in moving to cloud-based data platform is in ingestion of the data with a faster and secured approach since most of the data are available on-premises databases such as RDBMS.

We took this opportunity to build a custom script or leverage an existing platform based script to achieve the following outcomes.
- Efficiently ingest data from the source database (in our case MS SQL server)
- Custom partitioning of source data to provide extra structure to the data which results in efficient querying
- Manage to perform incremental append of data periodically upon ingestion
- Ingest particular data from the source when necessary
- Cost-effective ingestion approach
Based on our research, the above-mentioned outcomes could be achieved using one of the following options :
- AWS Lake Formation
- A custom spark script leveraging AWS Glue
AWS Lake Formation:
Using AWS Lake Formation, ingestion is easier and faster with a blueprint feature that has two methods as shown below.
i] Database Snapshot (one-time bulk load):
As mentioned above, our client uses SQL server as their database from which the data has to be imported. We used Database snapshot (bulk load), we faced an issue in the source path for the database, if the source database contains a schema, then the database / schema / table format should be used.
Moreover, wildcard (%) can be used for schema or table. We can exclude particular table names using exclude patterns.
ii] Incremental Import:
To ingest incremental data from the source, input the specified parameters as shown below :
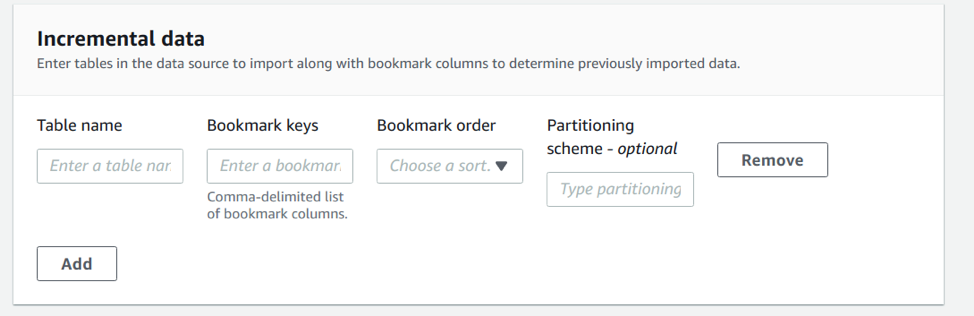 Bookmark key is the name of the table column to be checked for the last imported value which the data can be appended. Data Partitioning can also be achieved as an option. After importing, the user can query the table directly in Athena and check the imported data.
Bookmark key is the name of the table column to be checked for the last imported value which the data can be appended. Data Partitioning can also be achieved as an option. After importing, the user can query the table directly in Athena and check the imported data.
Note:
Instead of using a database snapshot (bulk load), we can use incremental import in the first step by mentioning the bookmark job (Unique or Primary column name) with partitions if present. For the next incremental append, Glue will be ready with the metadata from the previous run.
In addition to blueprint, AWS Lake formation offers data security and multiple user collaboration.
Security
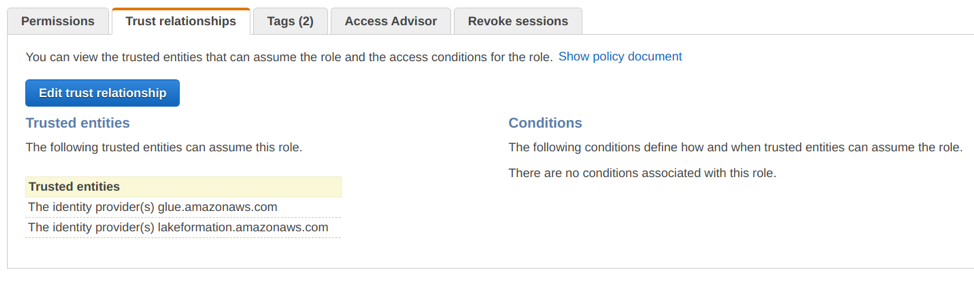
When a workflow is added via blueprint, the user has to set Data permission for the principal IAM role to Alter, create and drop table and grant permission for the same. Although we granted permissions for the Principal IAM role, we were faced with an entity trust relationship (even the AWS documentation does not mention this specific step at this point in time), we took the support of AWS and added a trust relationship to the principal IAM role.
Multiple user collaboration:
AWS Lake Formation allows users to restrict access to the data in the lake. The Data lake administrator can set different permission across all metadata such as part access to the table, selected columns in the table, particular user access to a database, data owner, column definitions and much more
For more information on sections referred above, please visit https://aws.amazon.com/blogs/big-data/building-securing-and-managing-data-lakes-with-aws-lake-formation/
Key Takeways
1.We were able to achieve most of our requirements using AWS Lake Formation. We ingested the data in an effortless way where our incremental import challenge was solved using blueprint features.
2.In fact, there are no additional charges with the use of AWS Lake Formation aside from the costs of underlying services such as Amazon S3 and AWS Glue, and we only have to pay for the services that are used.
Challenges Faced
Although AWS Lake formation is an effortless approach, we have faced a number of challenges:
- The dump data contains data from the year 2000, but we were only required to import the dump data after 2017. AWS lake formation at this point has no method to specify the where clause for the source data (even if the exclusion patterns are present to skip specific tables)
- Partitioning of specific columns present in the source database was possible in the formation of AWS Lake, but partitioning based on custom fields not present in the source database during ingestion was not possible.
- Using AWS Lake Formation, we faced administrative overhead to delete or track the job.
- When creating a workflow, Lake Formation creates multiple jobs in the console, thereby inducing manual workload.
A custom spark script leveraging AWS Glue:
To overcome all of these, we created a custom spark script leveraging AWS Glue that provided us with a flexible approach.
Most common scenarios involving rapid ingestion of data were much easier with AWS Lake Formation. But when a little more customization is required, we followed a customized approach to creating a spark script with AWS Glue.
Written by : Dhivakar Sathya & Umashankar N

