‘Data is the new oil’, depicts the fact that data stored in on-premises databases for a longer period has immense potential to solve business challenges. Data quality is of the utmost importance in order to obtain meaningful results from the data. Data quality is also a measure of the accuracy, validity and completeness of data. In this blog, we have highlighted some of the challenges faced in improving the quality of data.
- The occurrence of duplicate data
- Null values and Outliers in the data
- Inconsistency of attributes.
To overcome these challenges, we leveraged Data Profiling.
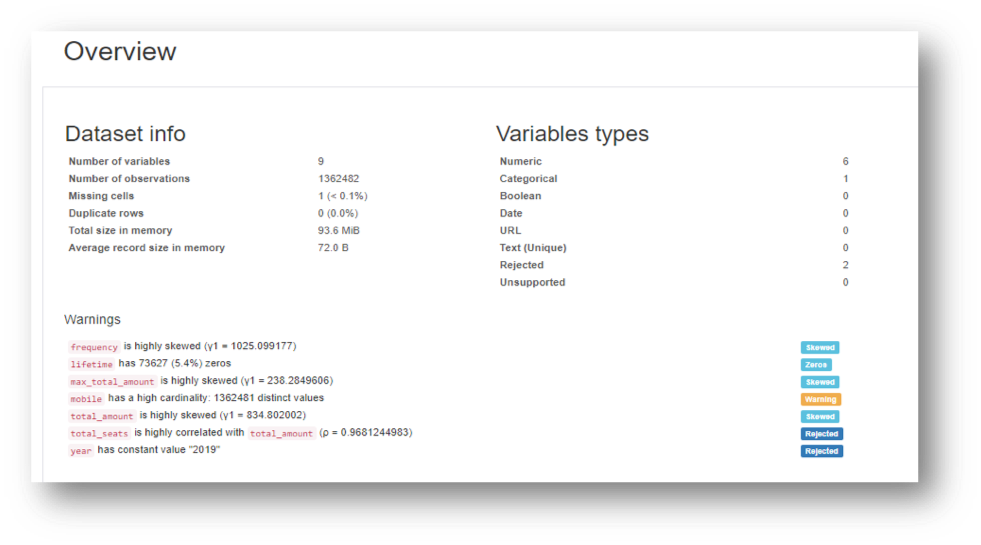
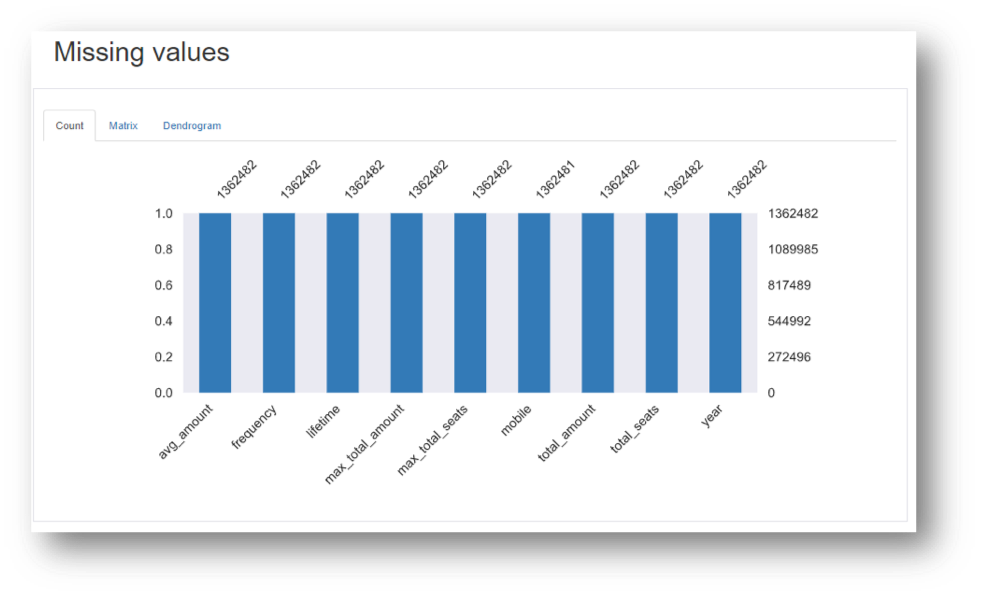
Data Profiling is a process of examining data from an existing source and summarizing information about that data. The data profiler provides
- Details about the attributes, distribution of data, missing data.
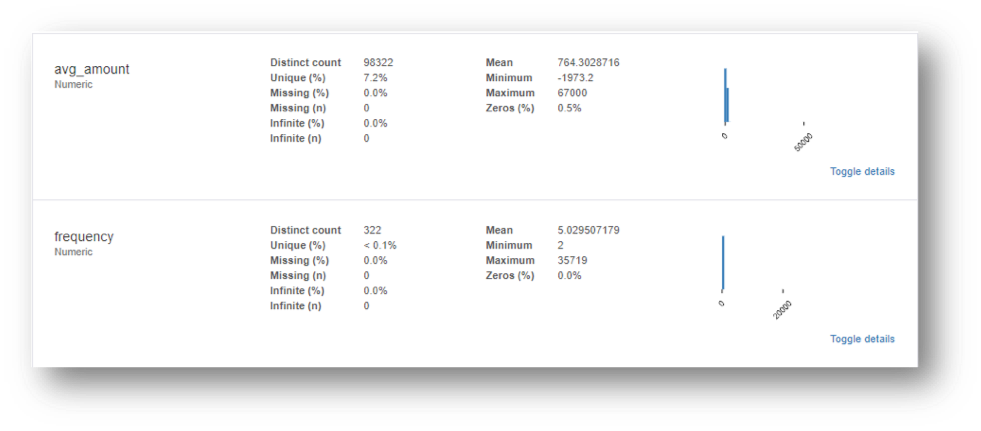
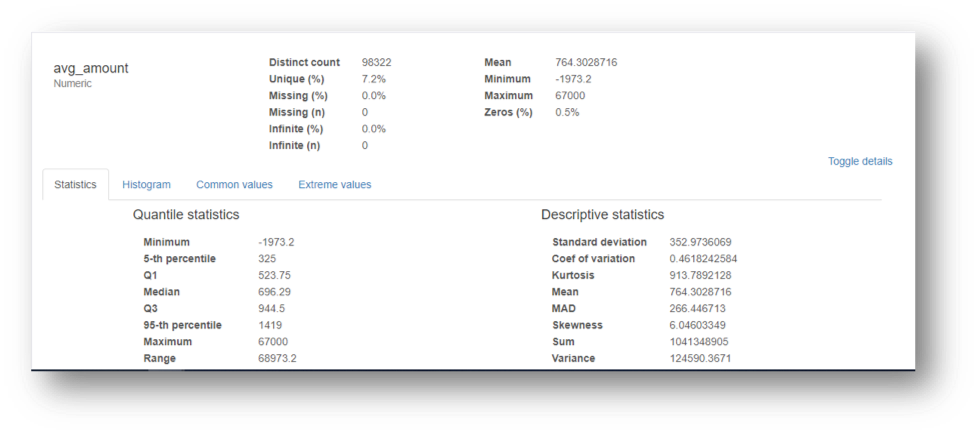
- Maximum, minimum and average values of each attribute.
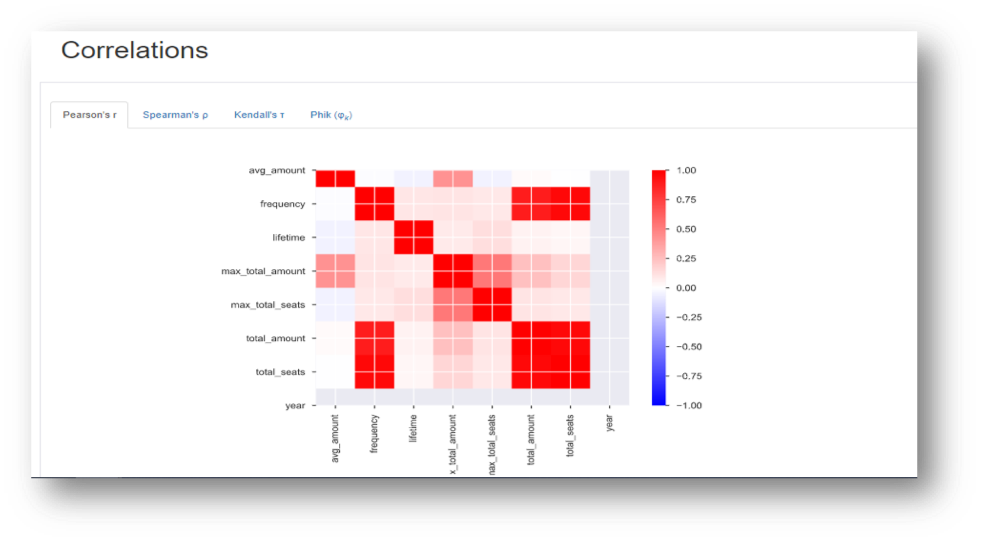
- Relationship between the attributes by correlation matrix, histogram analysis, whether it is categorical or numerical.
The following are the insights of Data Profiling on a sample dataset