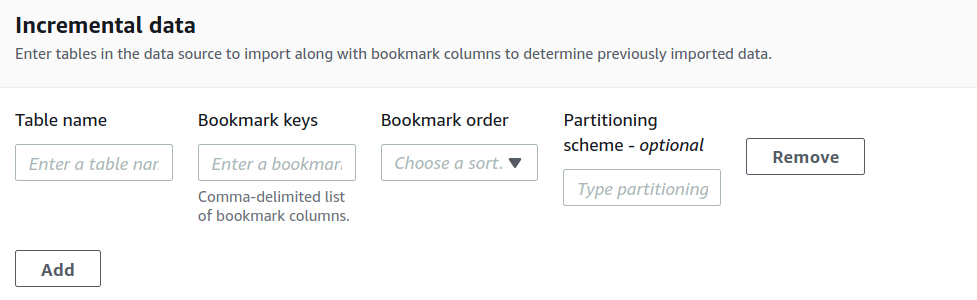
With growing numbers of people accessing data, it is important that data platforms are flexible and scalable. Hence people switch to cloud to achieve these objectives without compromising on security. However, the key challenge in moving to cloud-based data platform is in ingestion of the data with a faster and secured approach since most of the data are present across on-premises databases such as RDBMS. The cloud-based data lake opens the structured and unstructured data for more flexible analysis. Analysts and data scientists can then access it with the tools of their choice.
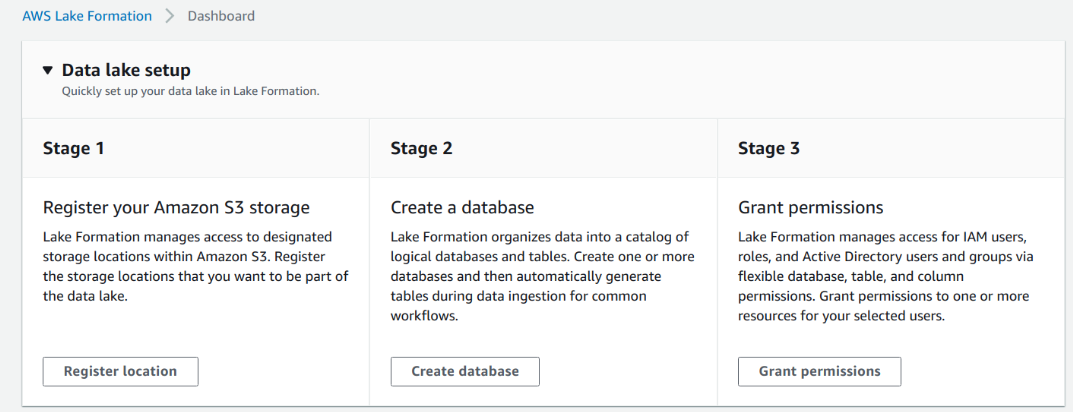
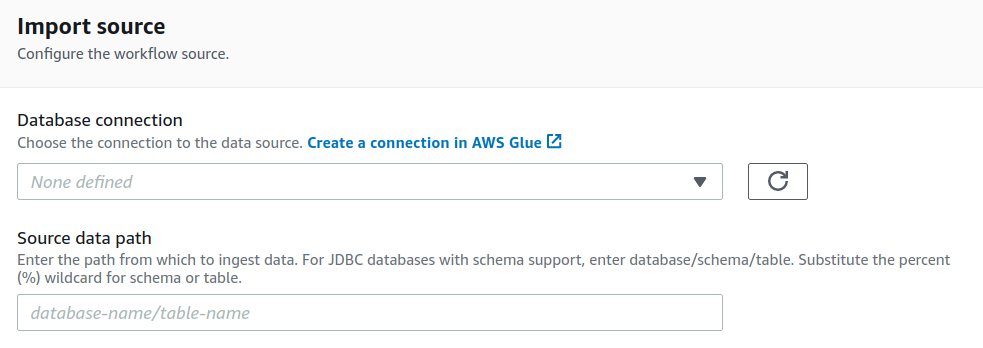
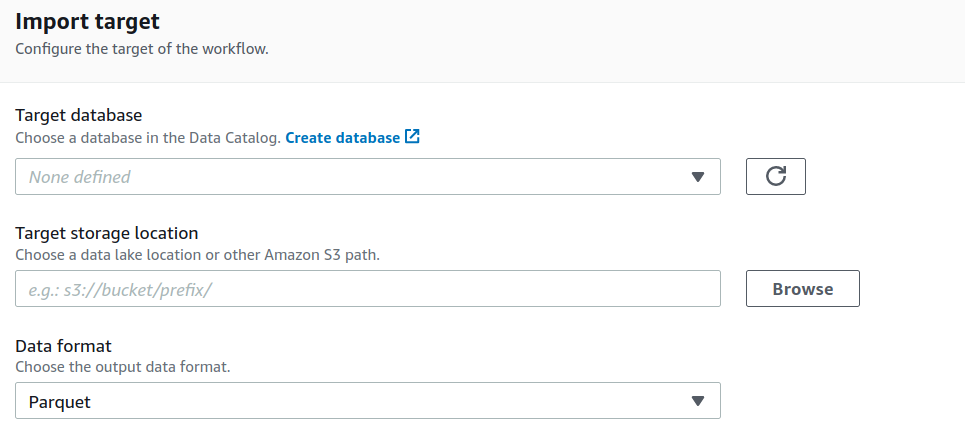
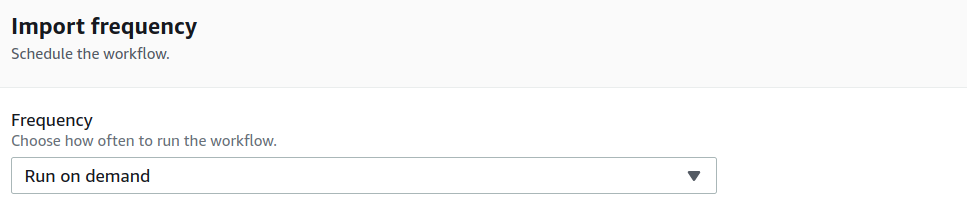
The conventional way of building a Data Lake involves setting up a large infrastructure, securing the data which is a time-consuming process and not a cost-effective approach. Even building a data lake in the cloud requires several steps:
- Setting up storage.
- Moving, cleaning, preparing the data.
- Configuring and enforcing security policies for each service.
- Manually granting access to users.
This process is tedious, it’s easily error-prone and not stable.