Dependent lookups in Business Intelligence (BI) applications are a type of field relationship in which the options in one field are determined by the selection made in another field. For instance, in a sales data set, the options in the “Region” field may be based on the selection made in the “Country” field. This creates a dynamic, multi-level reporting and analysis process, enabling more accurate and relevant data representation.
Build a Scalable GraphQL API with Multiple Dependent Lookups
Building a Scalable and Efficient GraphQL API with Dependent Lookups Using Stored Procedures and AppSync
Multiple Dependent Lookups
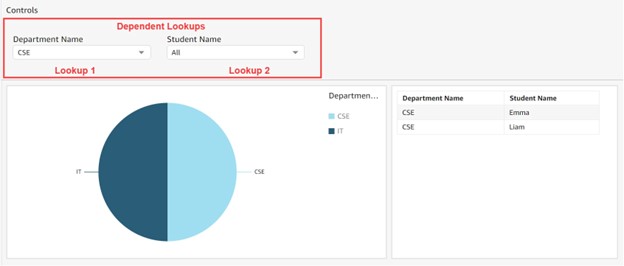
Dependent lookups using RestAPI?
Traditional REST APIs required multiple requests to retrieve data for multiple dependent lookups, increasing latency and slowing performance.
It’s difficult to manage complex relationships between data and validate data correctly. With traditional REST APIs, it was difficult to specify exactly what data was needed, leading to inflexible queries and inefficient data retrieval.
Why GraphQL over Rest API?
Dependent lookups in GraphQL API create a relationship between two fields, where the options in one field depend on the selection in another. This results in a more efficient and accurate user experience, as well as reducing the amount of data transferred and improving performance.
GraphQL’s flexible structure allows for easy modification of fields and relationships, making the application more adaptable.
5 Reasons to use stored procedures to handle multiple dependent lookups in a GraphQL API
Reusability

Stored procedures can be reused across multiple applications, which can be helpful if you have multiple systems that need to access the same data.
Data integrity
Stored procedures can be used to enforce data integrity constraints, which can be helpful in maintaining the consistency and accuracy of the data.
Performance
Stored procedures can often be more efficient than running multiple separate queries, especially for complex or resource-intensive operations. This can be especially beneficial in situations where the data set is large, or the number of dependent lookups is high.
Maintenance

Stored procedures can make it easier to maintain and update the data access logic, as the changes can be made in one place rather than in multiple application queries.
Business logic

Stored procedures can be used to encapsulate the business logic, which can be helpful for separating the data access logic from the application logic.
Approaches to retrieve Data
Advantages and Challenges of Dynamic Resolvers
Dynamic resolvers with dynamic where clauses can handle multiple dependent lookups effectively. Advantages include scalability, ease of deployment and monitoring, and better separation of concerns. However, it may require more resources as the logic is executed on the application server.
Leveraging Stored Procedures in GraphQL APIs for Improved Performance
Stored procedures can encapsulate complex business logic, increase code readability, and be used across multiple applications. In a GraphQL API, they can handle multiple dependent lookups and perform complex data manipulation tasks efficiently.
Using GraphQL with AppSync and RDS Aurora PostgreSQL can provide a scalable and performant API suitable for large data sets and handling high volumes of requests.
Consider the below table in RDBMS, When you want to create this as a filter(DL)
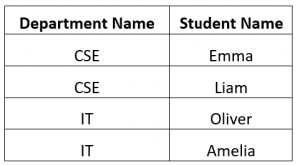
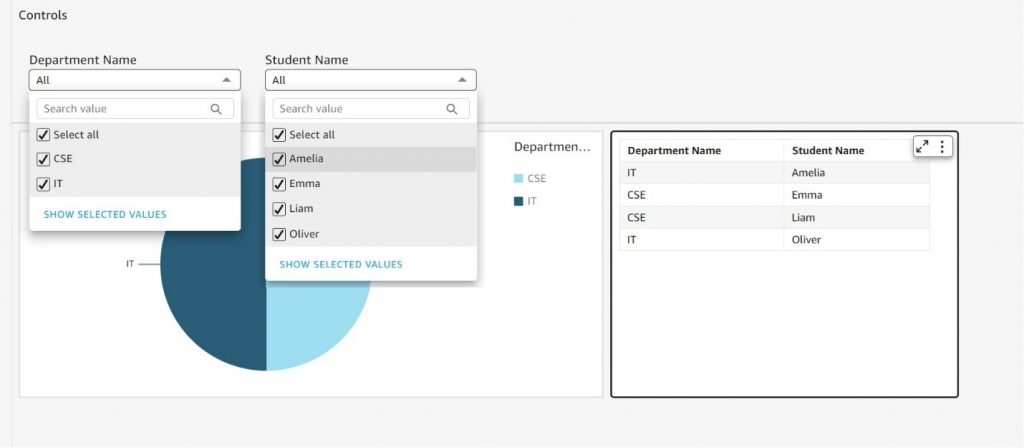
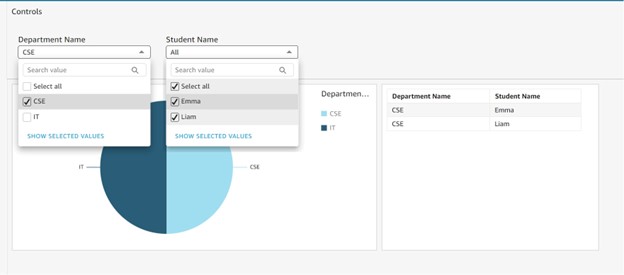
Overall, the use of GraphQL enables more efficient and flexible data retrieval, while AppSync and RDS Aurora PostgreSQL allow for the construction of a scalable and performant API that handles a high volume of requests making it suitable for applications with large data sets.
Stored procedures in GraphQL can improve the performance of data processing by offloading complex logic to the database, increasing security by allowing for the enforcement of business rules and constraints at the database level, and enhancing maintainability by encapsulating complex logic within a single, reusable component.
Reference
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/data-api.html
https://advancedweb.hu/how-to-use-rds-as-a-data-source-for-appsync/
Written By: Umashankar N , Karthikeyan G and Naveen Kumar G
If you have any questions or suggestions, please reach out to us at contactus@1cloudhub.com
Tags:
